| Linked lists - description |
| A linked list is a dynamic
data structure, which means that the memory to hold
the data is created at run time ( dynamic ), and stored
in a structured way ( data structure ). The items in a
linked list do not have to be stored in contiguous memory
locations like an array. Each item in the list is called
a node, which contains data as well as a
pointer to the next node in the list ( a link
pointer ). Normally there is only one variable
that is associated with a linked list, which is a pointer
variable to the first node in the list. From this point,
the links in the list can be followed until the desired
node is found. The last node in the list doesn't point to
another node, but points to NULL,
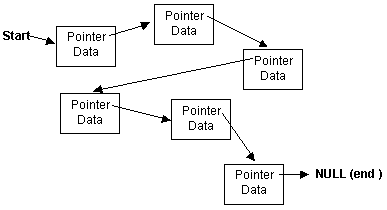
indicating the end of the list. The diagram below shows
this a lot better than this expanation :
In the diagram, each node is shown in the rectangles and contains a pointer to the next node in the list ( shown by the arrows ), and a data portion which holds the information for the node. The nodes are deliberately drawn in the diagram in a hap-hazard way to show that each node can exist in any portion of memory, not necessarily adjacent to or even close to the neighbouring nodes in the list. The start of the list is also shown, which is just a pointer to the first node. From this start pointer any node can be referenced, for all but the first node though, other nodes will have to be "passed through" to get there. The end of the list is indicated by the final node pointing to NULL. Normally, when a linked list is initialised, the start pointer will hold NULL to indicate that the list is empty, but as soon as a node is added to the list, this changes. The basic operations on a linked list are to add nodes and delete nodes :
These two basic operations are explained below. There are a number of ways of implementing these operations though, but i'll try to keep this as simple as possible for this. |